
Par Obim Okongwu
Introduction
Depuis peu, l’intelligence artificielle (IA) pique la curiosité de tout le monde. Bien que l’élément à l’origine de toute cette attention ait été les capacités de l’IA générative et des grands modèles de langage ainsi que des assistants virtuels comme ChatGPT, il ne fait aucun doute que l’IA est prometteuse.
Qu’il s’agisse de sa capacité à fournir de l’information pour offrir de meilleurs soins de santé et orienter les décisions médicales, d’améliorer l’expérience client ou de mettre au point les méthodes de tarification et de sélection des risques, l’IA présente des avantages qui semblent infinis. En outre, elle facilite la compréhension de l’impact des changements climatiques, aide les conseillers financiers à tailler des solutions et des services sur mesure, améliore les activités de recherche et de développement conduisant aux découvertes scientifiques, génère des codes de programmation en plus de faire la synthèse de rapports. Certains estiment que l’IA pourrait transformer radicalement notre économie, notre société et l’humanité.
Ces avantages sont rendus possibles grâce à la masse de données à la disposition des algorithmes d’IA, qui continue de croître de façon exponentielle en raison de la numérisation. De plus, les coûts du stockage de données et de l’informatique ne cessent de baisser, tandis que l’on continue de créer des algorithmes toujours plus poussés.
Toutefois, malgré ses avantages et selon la situation, l’IA est une arme à double tranchant. Des doutes ont été soulevés quant à la fiabilité de l’IA. On s’interroge notamment sur la possibilité que les algorithmes d’IA détectent des biais subtils dans les données sur lesquelles ils s’entraînent, puis les amplifient considérablement. Les algorithmes d’IA peuvent détecter dans une masse de données des tendances incroyablement complexes. Les algorithmes peuvent être eux-mêmes assez complexes et cette opacité fait en sorte qu’il est parfois difficile d’apprécier et d’expliquer leur robustesse. La protection de la vie privée, la propriété intellectuelle et les questions juridiques sont autant de questions que soulève l’IA générative.
Les risques de l’IA
Non seulement l’IA présente les mêmes risques que ceux des modèles traditionnels, mais il se pourrait aussi qu’elle les exacerbe. La figure 1 qui suit illustre d’autres risques pouvant découler de l’adoption et de l’utilisation de l’IA.
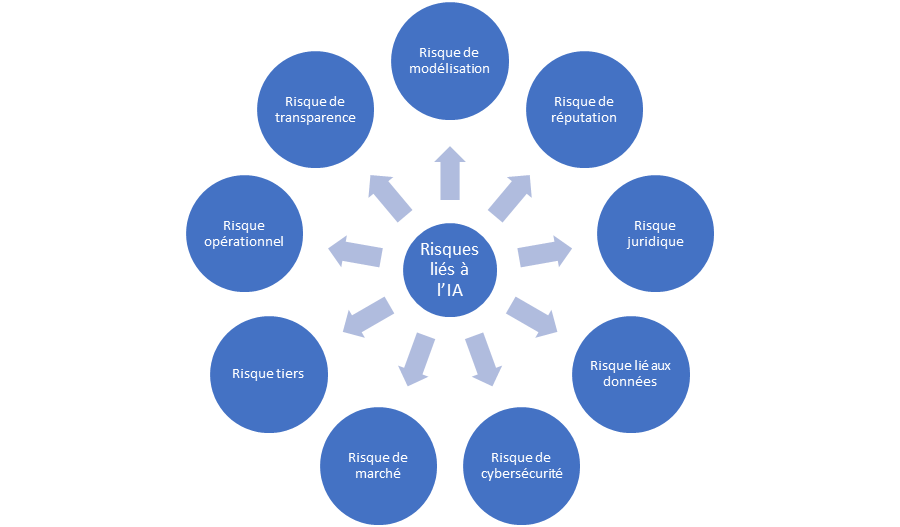
L’aspect positif de l’IA réside dans sa capacité à apprendre des tendances, même étonnantes, à partir d’une masse importante de données. Des problèmes surviennent si le modèle d’IA est surentraîné, si les données du monde réel ou de production ne correspondent pas aux données d’entraînement et aux tendances apprises ou que l’algorithme apprend quelque chose des données à l’insu des développeurs. Par conséquent, si l’un ou certains de ces problèmes surviennent, le risque d’obtenir des résultats erronés s’en trouve accru, surtout si le modèle est utilisé à des fins pour lesquelles il n’a pas été entraîné.
La complexité de certains algorithmes d’IA fait en sorte qu’il est difficile de comprendre comment les résultats sont produits, voire de les expliquer. L’autoapprentissage ou les modèles dynamiques qui apprennent en cours d’exécution posent encore de plus grandes difficultés.
Le volume même de données qu’utilise l’IA, qui ne cesse d’augmenter, de même que la variété et la vélocité des données, rend difficiles leur gouvernance et la préservation de leur intégrité et de leur qualité. Vu que les systèmes d’IA sont guidés par les données et sont davantage interconnectés, ils peuvent devenir plus vulnérables au piratage et aux cyberattaques. Des attaques par empoisonnement de données ou de modèles, qui s’effectuent par l’ajout d’échantillons spéciaux aux ensembles de données d’entraînement ou par l’intégration de logiciels malveillants à du code source libre, peuvent se produire afin d’induire en erreur les systèmes d’IA pendant leur fonctionnement ou créer des vulnérabilités.
Outre le piratage, qui met à risque les données privées, le désir même d’exploiter de plus en plus de données pour en tirer de l’information et des avantages pourrait mener à la collecte et à l’utilisation de données sans consentement, qu’elles soient privées ou non. L’IA a la capacité de démasquer des données anonymisées. En outre, les résultats des modèles d’IA peuvent divulguer des données sensibles de manière directe ou par inférence. Le pouvoir de l’IA de détecter des tendances étonnantes lui permet d’apprendre des biais subtils et de les magnifier, ce qui entraîne des conséquences imprévues. On avance l’argument d’exclure les variables protégées comme la race et le sexe, mais celles-ci peuvent être déduites par les algorithmes. Les allégations de discrimination découlant de résultats injustes et d’atteintes à la vie privée pourraient entacher la réputation d’une institution ou lui causer des problèmes judiciaires.
En l’absence de grandes équipes pour construire et valider des modèles d’IA, il est probable qu’on ait recours à des tiers. Cela vaut plus particulièrement pour les institutions de petite taille. Outre les modèles mêmes, les données de tiers pourraient susciter un intérêt accru chez les institutions cherchant à tirer parti des avantages de l’IA. L’utilisation de bibliothèques libres et de code source libre est inévitable. Tous ces facteurs augmentent le risque tiers et le risque de concentration. Une autre des choses inévitables est l’utilisation accrue de l’automatisation et d’une IA possiblement autonome ainsi que la dépendance à celles-ci. L’échec de processus automatisés ou de l’IA autonome peut avoir des conséquences importantes sur un processus en aval ou connexe; il faut donc prendre en compte les implications du risque opérationnel.
Réglementation de l’IA
Bien qu’il y ait eu une augmentation récente des appels à la réglementation de l’IA, née de la popularité des grands modèles de langage et de l’inquiétude qu’ils suscitent, les décideurs et les autorités de réglementation de par le monde ont mené plusieurs activités au cours des dernières années.
Réglementation à l’échelle mondiale
Les décideurs et les autorités de réglementation se sont penchés sur la façon de promouvoir les avantages économiques et sociaux de l’IA, tout en gérant ses risques et ses inconvénients et les difficultés qu’elle suscite, telles que les inquiétudes concernant les problèmes systémiques et les préjudices pour la population. Pour concilier ces objectifs, bon nombre d’entre eux ont commencé par publier des documents de travail, des documents de consultation, des principes et des rapports.
« Même si les quelques politiques et règlements qui portent spécifiquement sur l’IA sont à l’état préliminaire, il convient de faire remarquer qu’ils sont précédés d’une liste de principes. »
– Obim Okongwu
Ces politiques et règlements reposent habituellement sur les principes de la juridiction concernée et sur la participation de diverses parties intéressées. Bien que les approches qu’adoptent les juridictions puissent différer, certaines étant plus rigoureuses que d’autres ou fondées sur des principes plutôt que normatives, il semble qu’elles seront toutes fondées sur le risque.
L’Union européenne devrait finaliser cette année le tout premier cadre juridique complet sur l’IA. Sa loi sur l’IA est considérée comme étant la plus stricte et aura des retombées mondiales en raison du fait que les grandes entreprises sont multinationales. Les développeurs de systèmes d’IA dans d’autres pays voudront naturellement commercialiser leurs produits dans l’UE en raison de l’importance de son marché, qui compte près de 450 millions d’habitants et habitantes.
La loi de l’UE réglemente l’IA en fonction des catégories de risque suivantes : risque inacceptable, risque élevé, risque limité et risque minimal ou nul. Plus précisément, les algorithmes utilisés pour l’évaluation des risques et la tarification en assurance maladie et en assurance vie sont considérés comme présentant un risque élevé et doivent satisfaire à des exigences réglementaires plus strictes.
La réglementation au Canada
Au Canada, les politiques et la réglementation à venir qui auront une incidence sur le secteur financier sont la ligne directrice E-23 du Bureau du surintendant des institutions financières (BSIF) intitulée « Gestion du risque de modélisation à l’échelle de l’entreprise dans les institutions de dépôts » et la Loi sur l’intelligence artificielle et les données (LIAD) du projet de loi C-27.
Ligne directrice E-23 du BSIF
Bien que la ligne directrice E-23 n’ait pas encore été publiée, le BSIF a publié une lettre en mai 2022 sur les aspects à l’étude pour tous les modèles, y compris les modèles d’IA. Certains modèles sont élaborés par des algorithmes d’IA.
Vu que les données deviennent de plus en plus accessibles, que leur volume augmente et qu’elles servent à la modélisation, il s’agissait d’un point clé à prendre en considération, de la traçabilité à la gouvernance, en passant par la provenance et la qualité. On allait également tenir compte de la rigueur des développeurs, des valideurs et des approbateurs de modèles afin que le modèle mis en production soit robuste. On reconnaît également que les modèles d’IA peuvent amplifier les biais injustes dans les données, ce qui pourrait avoir des conséquences sur la réputation de l’institution.
Bien que la documentation soit importante pour la continuité des activités, le niveau de documentation proportionnel au risque de modélisation allait également être pris en compte. Compte tenu du fait que les institutions peuvent déjà avoir en place des structures de gouvernance, il fallait donc tenir compte de la mesure dans laquelle ces structures pourraient être améliorées. L’existence de différentes dimensions et de différents niveaux d’explicabilité a été prise en compte.
Dans tous ces cas, les conseils à publier seraient proportionnels au risque. De plus, il fallait prendre en considération la question de la proportionnalité.
La LIAD du projet de loi C-27
La Loi sur l’intelligence artificielle et les données (LIAD) a été déposée en juin 2022 dans le cadre du projet de loi C‑27, la Loi de 2022 sur la mise en œuvre de la Charte du numérique. Un document complémentaire a été publié en mars 2023.
« La LIAD reconnaît que, pour prospérer, l’économie du Canada doit être basée sur des données avancées et qu’elle a donc besoin d’un cadre dans qui inspire la confiance de la population, encourage l’innovation responsable et demeure interopérable avec les marchés internationaux. »
– Obim Okongwu
La LIAD reconnaît que, pour prospérer, l’économie du Canada doit être basée sur des données avancées et qu’elle a donc besoin d’un cadre dans qui inspire la confiance de la population, encourage l’innovation responsable et demeure interopérable avec les marchés internationaux.
Elle traite de deux types d’impacts négatifs : 1) les préjudices causés aux personnes (préjudices physiques ou psychologiques, dommages matériels ou pertes économiques); 2) les biais systémiques dans les systèmes d’IA dans un contexte commercial lorsqu’il y a une différenciation défavorable injustifiée fondée sur l’un des motifs de distinction interdits dans le cadre de la Loi canadienne sur les droits de la personne.
À l’instar de la loi de l’UE sur l’IA, elle sera fondée sur les risques, mais axée sur les systèmes dont l’impact est élevé. Parmi les éléments à prendre en considération pour déterminer si un système a un impact élevé, mentionnons l’existence d’un risque de préjudice, la gravité du préjudice potentiel, l’ampleur de l’utilisation et la mesure dans laquelle il n’est pas possible de se retirer de ce système.
Il y aura des attentes envers les entreprises qui conçoivent ou élaborent un système d’IA à impact élevé, envers les entreprises qui le commercialisent et envers celles qui gèrent son fonctionnement. Ces attentes porteront sur l’identification, l’atténuation, la documentation, la surveillance et la communication des risques et elles reposeront sur un ensemble de principes de la LIAD. En cas de non-conformité, il pourrait y avoir des sanctions pécuniaires ou des infractions réglementaires pouvant faire l’objet de poursuites.
Principes pour une utilisation responsable de l’IA
Des décideurs, des autorités de réglementation et des organismes de divers pays ont mis en évidence les principes visant à atténuer ces risques et à favoriser l’adoption et l’utilisation responsables de l’IA. Les principes mis en évidence par les décideurs et les autorités de réglementation canadiennes sont en phase avec ceux des autres juridictions. La figure 2 qui suit présente divers principes, à l’échelle mondiale ou canadienne.
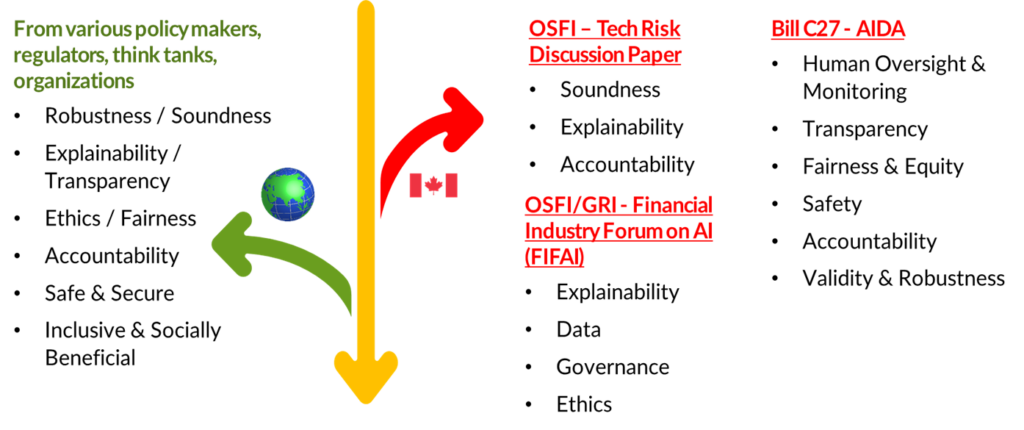
Au Canada, le BSIF a cité trois principes (solidité, responsabilité, explicabilité) dans son document de travail sur le risque technologique de 2020. Ils ont été suivis de quatre principes (explicabilité, données, gouvernance, éthique) énoncés à l’occasion du Forum sur l’intelligence artificielle dans le secteur des services financiers (FIASSF) organisé par le BSIF et le Global Risk Institute. Publié en avril 2023, le rapport du FIASSF s’intitule « Une perspective canadienne sur l’intelligence artificielle responsable ». Le document complémentaire de la LIAD énonce six principes d’IA : supervision humaine et surveillance, transparence, justice et équité, sécurité, responsabilité, validité et robustesse.
Les principes qui sous-tendent l’utilisation de l’IA tendent à orienter les politiques et la réglementation, et le document complémentaire de la LIAD indique que les attentes seront guidées par l’ensemble de principes énoncés. Les institutions pourraient s’inspirer de ces principes pour concevoir ou améliorer leur cadre de gestion du risque de modélisation. Voici quelques observations concernant certains de ces principes.
- La robustesse ou la solidité permettent de s’assurer que le modèle est fiable et fonctionne comme prévu lorsqu’il est exécuté dans diverses situations, fussent-elles extrêmes[1].
- L’explicabilité et la transparence englobent la compréhension des données utilisées pour entraîner le modèle, le fonctionnement interne du modèle et ses résultats. Elles englobent également la communication proactive d’informations détaillées pertinentes et appropriées aux diverses parties intéressées et dans un « langage » que la partie est en mesure de comprendre.
- L’éthique a pour but de faire en sorte que les résultats du modèle soient justes et sans biais négatifs. Elle comprend également la protection des renseignements personnels et la question du consentement.
- Les données englobent les considérations relatives à la qualité, à la provenance, à l’exhaustivité, à la protection des renseignements personnels et au consentement pour une utilisation éthique, tous les éléments importants rendus possibles par une saine gouvernance des données.
- La responsabilité et la gouvernance ont pour but de faire en sorte que les bonnes personnes ou les bonnes équipes participent et soient responsables tout au long du cycle de vie du modèle et qu’il y ait en place des politiques et des structures de gouvernance, et donc à ce que tous les principes d’adoption et d’utilisation responsables de l’IA soient respectés.
- L’adjectif sûr qualifie une IA qui ne présente pas de danger pour les personnes et les entreprises, compte tenu de l’exposition aux cybermenaces en raison de l’utilisation accrue des données et de la numérisation.
- L’IA doit profiter à tous et toutes et contribuer à la croissance et à la prospérité générales de la société.
Regard sur l’avenir de l’IA
Nul doute que l’innovation et la sophistication de l’IA se poursuivront et que les entreprises devront en tirer parti pour rester concurrentielles. Les risques pouvant être exacerbés par ces progrès et cette utilisation, les appels à la réglementation de l’IA ont augmenté ces derniers mois de la part de chercheurs renommés en IA et de dirigeants d’importantes entreprises d’IA.
Les autorités de réglementation et les décideurs de diverses juridictions continueront d’agir pour assurer la solidité de leurs institutions et protéger leurs populations.
Comment l’IA a-t-elle transformé votre lieu de travail et votre domaine de spécialisation? Faites‑nous part de vos réflexions dans la section des commentaires, ou communiquez avec nous à voiraudeladurisque@cia-ica.ca si vous souhaitez participer à la rédaction d’un article que nous publierons sur le blogue Voir au‑delà du risque.
[1] Les situations extrêmes sont rares, tandis que les situations probables ont une faible probabilité d’occurrence.



